랩뷰 2019 버전부터 2가지 데이터 타입을 지원하기 시작했는데요. SET과 MAP이라는 데이터 타입입니다. 새로 지원하는 데이터 타입인지라 어떤 특성을 가진 데이터 타입인지를 확인하기 위해 랩뷰 공식 기술 문서를 찾아 봤습니다만, 블록 다이어그램에서 사용하는 메뉴에 대한 설명만 있을 뿐, 데이터 타입에 대한 기본적인 내용은 찾을 수 없었습니다. 랩뷰에 관한 내용을 주제로 하는 여러 기술 블로그들의 정보도 찾아 봤습니다만, 영어로 되어 있는 몇 개의 블로그만 검색될 뿐, 두 데이터 타입에 대한 내용은 거의 전무한 상태에서, 결국 직접 테스트를 통해 내용을 파악해 보기로 하였습니다.
SET 데이터 타입
서두에 말씀드렸듯이, SET 데이터 타입에 대해 참고할만한 수준의 정보를 찾을 수가 없었습니다. 그래서, 개인적으로 테스트를 통해 파악한 내용을 토대로 이 글을 작성한다는 점 참고하시기 바라구요. 만약, 본 글에 대한 내용에서 정정이 필요한 부분이 있으시면 언제든지 댓글을 통해 지적해 주시면 확인 후 반영토록 하겠습니다.
개인적으로는 랩뷰에서 SET라는 데이터 타입을 처음 봤을 때, 파이썬의 SET 타입을 먼저 연상하였습니다. 그리고, 먼저 말씀드리고 시작하겠습니다만, 기대했던대로 파이썬의 SET 타입과 같다고 말씀드릴 수 있을 정도로 거의 유사합니다. 하지만 이 글을 읽고 계신 분들 중에서는 파이썬을 모르는 분들도 있을테니 SET 타입에 대해 하나씩 알아가 보도록 하겠습니다.
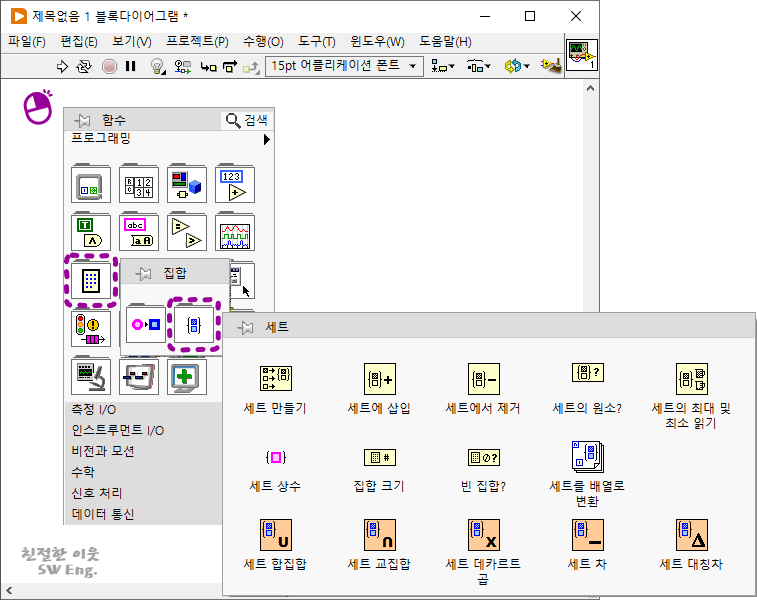
SET라는 데이터 타입과 관련해서, 위 그림과 같이 함수 팔레트의 프로그래밍 → 집합 → 세트에 가면 SET 타입과 관련된 함수들을 찾으실 수 있는데요. SET 타입이 어떻게 구성되었는지를 확인하기 위해, 세트 상수를 선택해서 블록 다이어그램에 추가해 보겠습니다.

위 그림은 블록 다이어그램에 세트 상수를 추가한 화면인데요. 처음에는 왼쪽의 그림처럼 아주 작은 형태로 블록 다이어그램에 추가됩니다만, 내부 원소의 크기를 조정하면 오른쪽 그림처럼 크게 만들 수 있습니다. 하지만, 세트 상수 내부 원소들의 값을 직접 정의할 수는 없습니다. 쉽게 말해서, 프로그램에 상수 데이터를 추가했는데, 어떤 값을 가진 상수 데이터인지를 정의할 수는 없다는 의미인데요. 이 부분은 개인적으로도 참 이해가 안되는 부분 중 하나인 것이, 파이썬에서의 SET 데이터는 중괄호를 이용해서 내부 원소들을 직접 정의할 수 있습니다만, 랩뷰에서는 상수라 할지라도 사용자가 직접 정의하지 못하도록 막고 있습니다. 그래서, 프런트 패널에 추가한 세트 타입의 오브젝트 또한 초기화 자체가 불가능합니다. 다만, 원소의 데이터 타입을 변경하는 것은 가능합니다.

프런트 패널이나 블록 다이어그램에 추가된 세트 상수에 데이터를 임의로 기록할 수는 없지만, 이들 오브젝트는 사용처가 나름대로 있습니다. 프런트 패널의 오브젝트의 경우에는 다른 VI와 데이터를 주고 받기 위한 터미널로도 사용할 수 있을 것이구요. 블록 다이어그램에서는 세트 타입과 관련된 여러 함수들의 베이스 타입으로 사용할 수 있습니다. 그런데, 블록 다이어그램에 추가된 세트 상수의 색상을 통해 알 수 있듯이, 세트 타입은 기본적으로 문자열 타입의 데이터를 원소로 가지고 있습니다. 다시 말해, 기본 세트 타입으로 연산을 처리하게 되면 모두 문자열 타입을 베이스로 연산을 처리해야 한다는 말이 되지요.
만약, 문자열이 아닌 다른 데이터 타입을 가지고 연산을 처리하기 위해서는 베이스가 되는 세트 타입 원소의 데이터 타입을 변경해 주어야 합니다. 위 그림처럼 원하는 데이터 타입의 상수 오브젝트를 세트 상수 안으로 끌어다 놓으면 간단히 변경할 수 있는데요. 사소한 내용처럼 보일 수도 있지만, 나름 중요한 내용이니 꼭 기억하시기 바랍니다.

세트 타입의 오브젝트가 외부로 부터 데이터를 전달받기 위한 터미널 역할로 사용되거나, 관련된 함수들의 베이스 타입으로 사용된다는 점에서, 실질적인 세트 데이터의 정의는 다른 방식으로 된다는 것을 유추할 수 있습니다. 그것이 바로 세트 만들기 함수인데요. 위 그림과 같이 함수 팔레트에서 프로그래밍 → 집합 → 세트 → 세트 만들기를 선택하면 블록 다이어그램에 세트 만들기 함수를 추가할 수 있습니다.
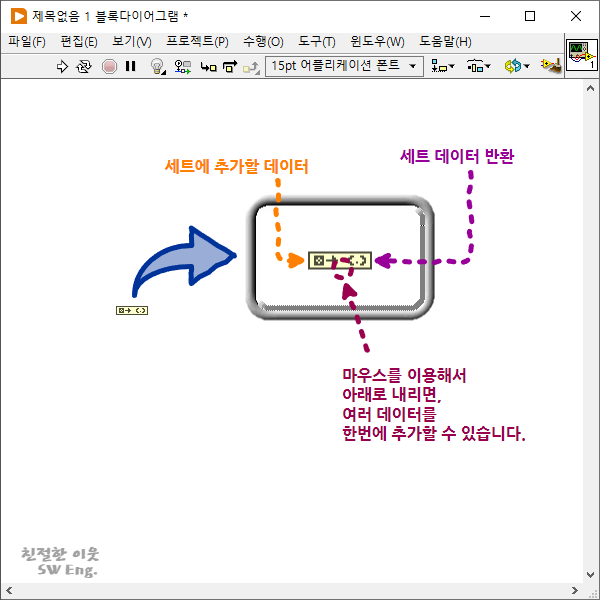
세트 만들기 함수는 배열 만들기 함수와 마찬가지로, 원소로 사용할 데이터를 입력 터미널로 전달 받아서 하나의 세트 타입의 데이터를 출력으로 반환합니다. 그리고 마우스를 이용해서 함수를 위 아래로 늘려주면, 여러 데이터를 한 번에 입력 받아서 원소로 추가할 수도 있습니다.

세트 만들기 함수에 대한 동작은 위 그림을 통해 확인하실 수 있는데요. 3개의 문자열 컨트롤 오브젝트로부터 전달된 데이터들이 원소로 추가된 세트 타입의 데이터를 생성할 수 있습니다. 그런데 여기서 특이한 점 하나를 발견할 수 있는데요. 세트 만들기 함수에 연결된 데이터 순서와 세트 데이터 타입의 원소 순서가 다르다는 점입니다. 이 부분은 비교를 위해 함께 작성한 배열 만들기 함수의 실행 결과를 통해 확실히 알 수 있는데요. 배열 만들기 함수에 연결된 데이터의 순서와 동일한 순서의 배열이 출력으로 반환된 것과 다르게 세트 타입에서는 그렇지 않습니다.
이 테스트를 통해, 세트 타입에서는 인덱스 번호를 이용해서 데이터를 관리하지 않는다는 것을 알 수 있구요. 그래서 세트 타입과 관련된 함수들에서도 인덱스와 관련된 함수는 찾아볼 수 없습니다. 인덱스로 데이터를 관리하지 않기 때문에, 굳이 입력된 순서대로 데이터를 정렬할 필요도 없구요. 오히려 세트 타입에서는 ABC 순으로 데이터를 정렬합니다.
그렇다면 세트 타입의 데이터는 어떻게 관리되는지를 알아봐야 하는데요. 인덱스로 데이터를 관리하지 않기 때문에 세트 타입의 특정 인덱스의 데이터를 콕 찍어서 변경하는 것은 불가능합니다. 더 정확히 표현하자면 데이터를 순서에 따라 관리하지 않기 때문에 특정 위치라는 것 자체가 무의미 하구요. 그래서 새로운 데이터를 세트 타입에 추가하거나 기존의 데이터를 삭제하는 정도로만 데이터를 관리합니다.

세트 데이터에 새로운 원소를 추가하거나 삭제하는 함수와 이들의 실행 결과를 위 그림에서 확인하실 수 있는데요. 사용 방법이 그렇게 어렵지 않으므로 구체적인 설명은 생략하겠습니다. ㅎㅎ
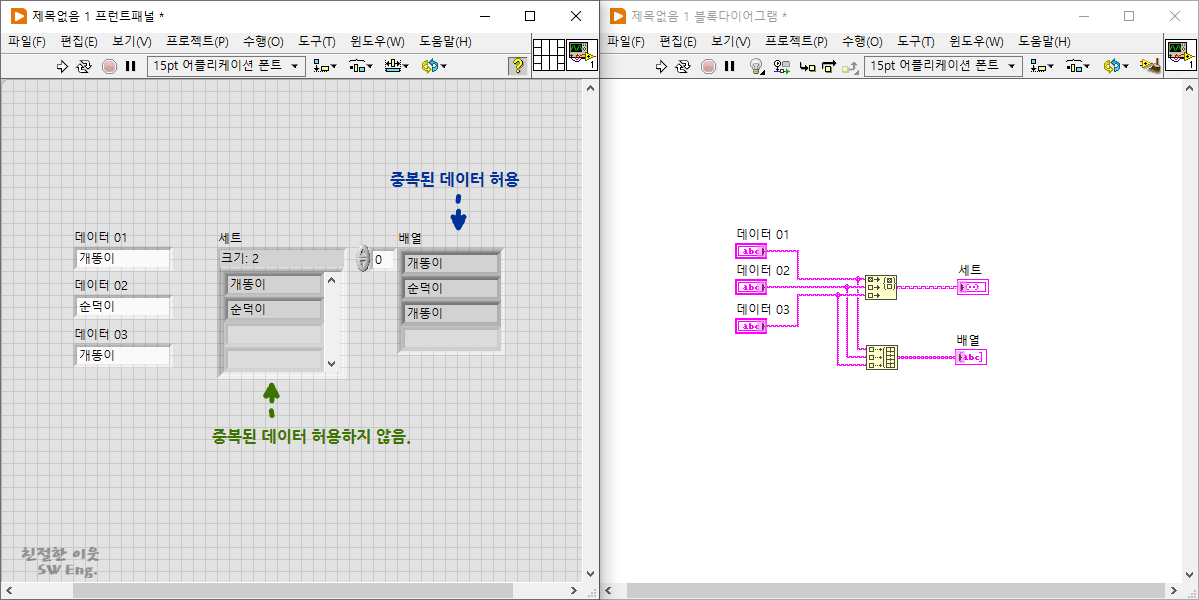
세트 타입이 가지고 있는 또 다른 재미난 특징은 중복된 데이터를 허용하지 않는다는 점입니다. 위 그림의 프로그램 실행 결과에서 알 수 있듯이, 중복된 데이터를 가지고 세트 데이터와 배열 데이터를 생성했을 때, 배열에서는 중복된 데이터를 허용하지만, 세트에서는 허용하지 않는데요. 수학에서 쓰이는 집합에서도 중복되는 원소를 집합에 포함하지 않는다는 것을 보면 이해가 되는 대목이라 할 수 있습니다.
이쯤되면 랩뷰에서 왜 세트 타입을 지원하기 시작하였고, 세트 타입으로 과연 어떤 것들을 할 수 있을까에 대한 의문이 생기실텐데요. 세트 타입은 중복된 원소를 허용하지 않으므로, 프로그램 안에서 참조되는 고유한 데이터들의 목록으로 사용할 수 있습니다. 그래서, 배열 타입의 데이터를 세트 타입으로 변환하게 되면 중복된 데이터들을 제거할 수 있구요. 데이터 자체가 ABC 순으로 정렬되어 있기 때문에 원하는 데이터가 세트 안에 있는지 여부를 빠르게 확인할 수 있습니다.

아울러, 교집합과 합집합과 같은 집합 자체의 연산을 적용할 수 있기 때문에, 세트 데이터끼리의 연산을 통해 고유 값에 대한 목록을 빠르게 업데이트 할 수 있습니다.
'Programming > LabVIEW' 카테고리의 다른 글
| 랩뷰에서 파이썬 실행하기 (0) | 2024.05.27 |
|---|---|
| MAP 데이터 타입 (0) | 2024.05.27 |
| 배열 인덱스 함수와 배열 부분 대체 함수 (0) | 2024.05.26 |
| 배열 초기화 & 배열 만들기 함수 (0) | 2024.05.25 |
| SubVI (0) | 2024.05.24 |
