Map 데이터 타입
SET 타입을 주제로 작성한 이전 글에서도 밝혔듯이, 뒤늦게 지원하기 시작한 SET과 MAP이라는 데이터 타입에 대해 참고할만한 수준의 정보를 찾을 수가 없었습니다. 그래서, SET 타입도 그렇고, 이번 글에서 작성하는 MAP 데이터 타입에 대한 내용도 개인적인 테스트를 통해 파악한 내용을 토대로 작성한다는 점을 미리 밝혀드리구요. 만약, 본 글에 작성된 내용 중에서 정정이 필요한 부분이 있으시면 언제든지 댓글을 통해 알려주시기 바랍니다. 확인하는대로 반영토록 하겠습니다.
이전 글에서 말씀드렸듯이 SET 타입이 파이썬의 SET 타입과 많은 부분이 닮았습니다. 그렇다면 MAP 타입도...? 라고 생각하실 수 있는데요. 네. 파이썬의 Dictionary 타입과 많은 부분이 닮은 데이터 타입입니다. 파이썬에 대한 내용을 알고 계신 분들은 이 부분을 생각하시면서 본 글을 읽어보시면 좋을 것 같구요. 파이썬에 대해 모르시는 분들도 충분히 이해할 수 있도록 나름 풀어서 설명해 보도록 하겠습니다.
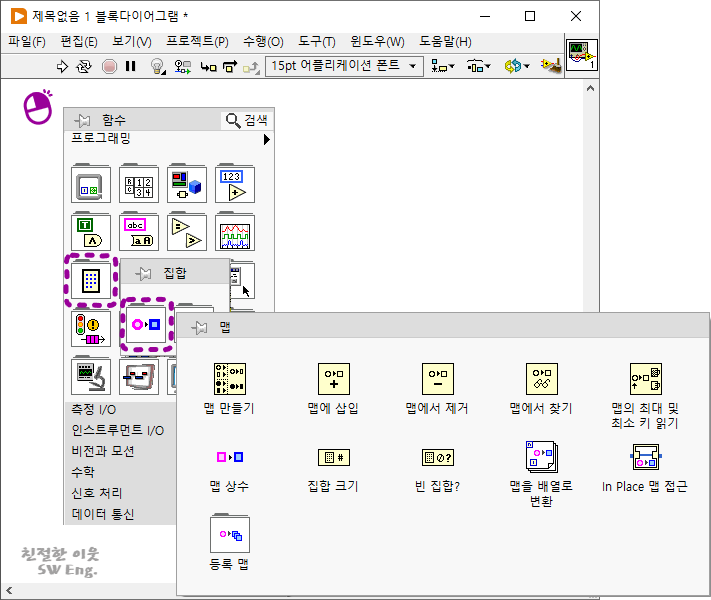
MAP이라는 데이터 타입과 관련해서, 위 그림과 같이 함수 팔레트의 프로그래밍 → 집합 → 맵에 가면 MAP 타입과 관련된 함수들을 찾으실 수 있는데요. MAP 타입이 어떻게 구성되었는지를 확인하기 위해, 맵 상수를 선택해서 블록 다이어그램에 추가해 보겠습니다.
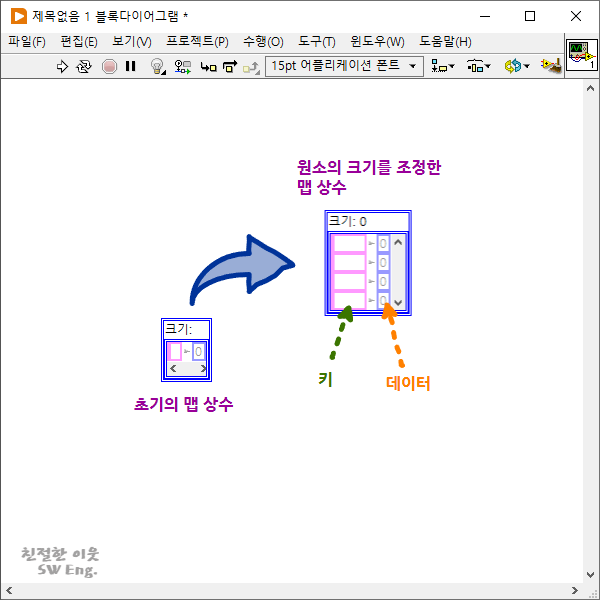
위 그림은 블록 다이어그램에 맵 상수를 추가한 화면인데요. 처음에는 왼쪽의 그림처럼 아주 작은 형태로 블록 다이어그램에 추가됩니다만, 내부 원소의 크기를 조정하면 오른쪽 그림처럼 크게 만들 수 있습니다. 그림에서 볼 수 있듯이 맵 타입의 데이터는 키와 데이터가 한 쌍으로 구성되어 있는데요. 앞에서 말씀드렸듯이 파이썬의 Dictionary 타입이 딱 이런 형태로 생겼습니다.
사전은 의미를 모르는 혹은 불확실하게 알고 있는 단어의 뜻을 정확히 파악할 때 사용합니다. 그래서 각각의 단어와 그 단어의 자세한 뜻을 서술해 놓은 구조로 되어 있는데요. 정확한 의미를 알고자 하는 단어를 검색하고 그 단어에 대해 서술해 놓은 뜻을 읽는 방식으로 사용합니다. 이런 사전에 대한 구조를 파이썬의 Dictionary와 랩뷰의 맵 데이터에 그대로 가져왔을 때 키라는 것이 사전에서의 단어를 의미하고, 데이터가 단어에 대해 자세하게 서술해 놓은 뜻 정도로 이해하시면 데이터 타입에 대한 구조나 사용 목적들을 어렴풋이나마 이해하실 수 있을 것입니다.
그런 의미에서 세트 타입과 닮은 부분도 있어 보이긴 하는데요. 우선, 블록 다이어그램에 상수를 추가하였지만, 내부 원소의 값을 사용자가 직접 정의할 수 없는 이해할 수 없는 부분도 닮았고, 특정 데이터 타입의 상수 오브젝트를 맵 상수 내부로 가져가면, 키 또는 데이터의 타입을 변경할 수 있다는 점도 닮았습니다.

그 말은 곧 세트 타입의 경우처럼, 맵 타입 데이터 역시 외부로 부터 데이터를 전달받기 위한 터미널 역할로 사용되거나, 관련된 함수들의 베이스 타입으로 사용된다고 볼 수 있는데요. 다시 말해, 실질적인 맵 타입의 데이터는 다른 방식으로 정의된다는 것을 의미합니다. 그것이 바로 맵 만들기 함수인데요. 위 그림과 같이 함수 팔레트에서 프로그래밍 → 집합 → 맵 → 맵 만들기를 선택하면 블록 다이어그램에 맵 만들기 함수를 추가할 수 있습니다.
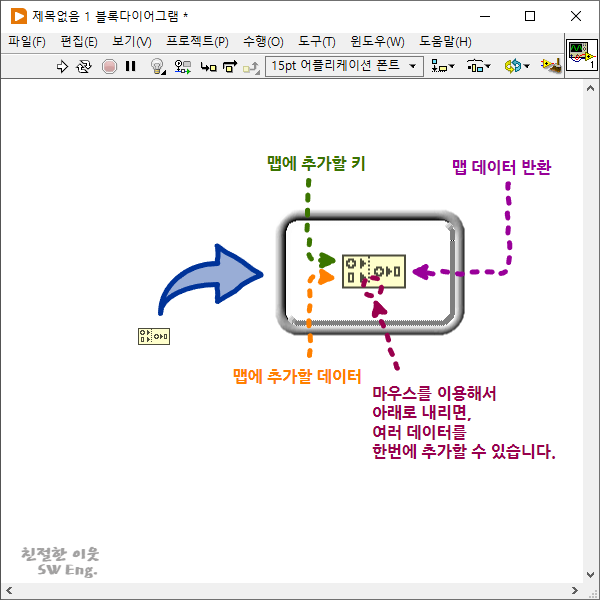
맵 만들기 함수는 세트 만들기 함수와 마찬가지로, 원소로 사용할 데이터를 입력 터미널로 전달 받아, 하나의 맵 타입 데이터를 출력으로 반환합니다. 차이가 있다면, 위에서 알아본 내용대로 맵 타입 데이터의 원소가 키와 데이터의 쌍으로 이루어져 있기 때문에, 기본적으로 입력 터미널이 2개이구요. 키와 데이터를 전달 받습니다. 아울러, 마우스를 이용해서 함수를 위 아래로 늘려주면, 한 번에 여러 원소를 가진 맵 타입 데이터를 생성할 수 있습니다.

맵 만들기 함수에 대한 동작은 위 그림을 통해 확인하실 수 있는데요. 정수형 데이터 (키)와 문자열 데이터 (데이터)를 쌍으로, 세 쌍의 데이터를 입력 터미널로 전달 받아서 이들이 원소로 추가된 맵 타입의 데이터를 생성할 수 있습니다. 여기서 재미난 부분은 키가 정수형 타입이고 데이터가 문자열 타입인데, 생성된 맵 타입 오브젝트는 문자열 데이터와 같은 색으로 표시된다는 점에서, 데이터의 타입을 따라간다는 것을 알 수 있습니다.

맵 타입 데이터가 가지고 있는 특징 중 하나가, 키 값에 의해 자동으로 데이터가 정렬된다는 점입니다. 위 그림을 통해 확인하실 수 있는데요. 맵 만들기 함수로 데이터가 전달되는 순서와 관계 없이, 키 값에 따라 내부적으로 자동 정렬된 것을 확인하실 수 있구요. 이 테스트를 통해, 맵 타입 데이터 역시 인덱스 번호를 이용해서 데이터를 관리하지 않는다는 것을 알 수 있습니다.

중복되는 데이터에 대해 위 그림과 같이 테스트를 해보면, 데이터가 중복되는 경우에는 모두 맵의 원소로 정의될 수 있지만,

중복되는 키에 대해서는 마지막에 전달된 데이터가 기록된다는 것을 알 수 있습니다. 다시 말해서, 여러 개의 원소를 하나의 그룹으로 묶어 놓은 데이터 타입이지만, 인덱스를 통해 데이터를 관리하지 않고, 중복된 키를 허용하지 않는다는 점에서 맵에 기록된 데이터들의 검색은 키를 통해 이루어진다는 것을 알 수 있구요.

세트와 마찬가지로 맵 타입의 데이터에서도 원소를 추가하거나 삭제하는 형태로만 데이터를 관리할 수 있습니다.
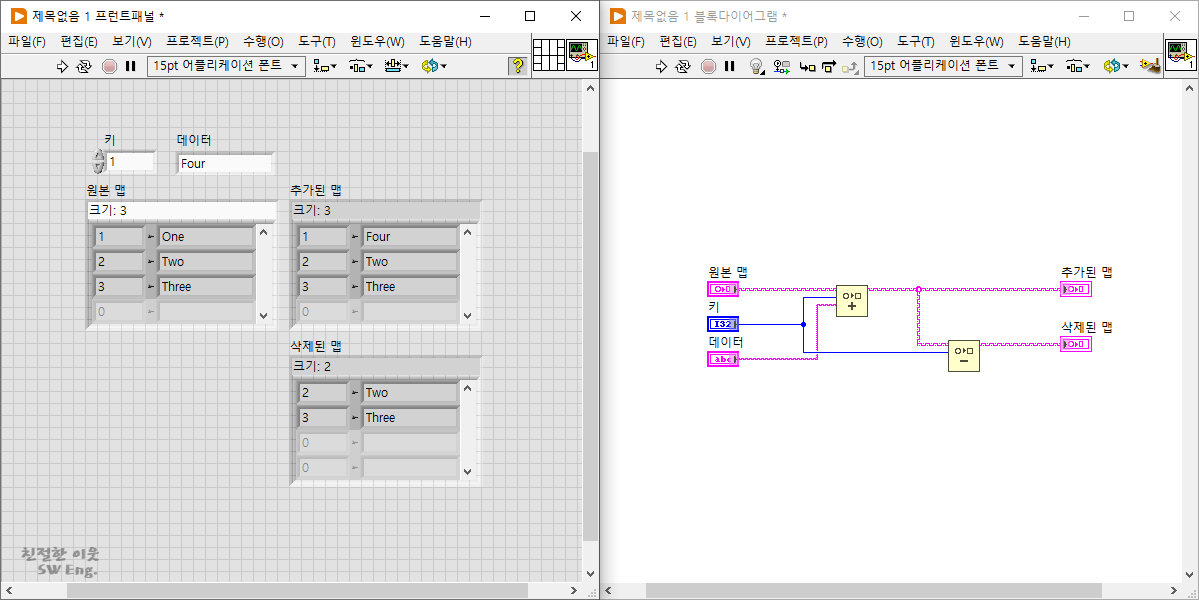
대신에, 중복된 키를 허용하지 않으면서 마지막 전달된 데이터로 덮어 쓰인다는 점을 이용하면, 기존에 정의된 키에 대한 데이터를 새로운 데이터로 변경할 수 있다는 점 참고하시기 바랍니다.
이전 글에 이어서 2개의 글을 통해 랩뷰에서 새로 지원하기 시작한 SET과 MAP 타입에 대해 알아보았습니다.이 글을 읽고 계신 분들은 아마도 랩뷰에서 왜 이런 데이터 타입을 지원하기 시작했는지에 대한 근본적인 의문과 어디에 적용할 수 있는지를 알아보기 위해 검색을 하는 과정에서 여기까지 도달하셨다고 생각하는데요. 서두에도 말씀드렸다시피, 뭔가 참고할만한 구체적이면서 공식적인 정보는 거의 찾아보기 어려웠으므로, 어디까지나 개인적인 경험에 비추어서 내용을 정리했다는 점 참고하시기 바랍니다.
이미 랩뷰에서는 오래 전부터 배열과 클러스터라는 2가지의 사용자 정의형 데이터 타입을 지원하고 있었습니다. 개발자가 약간의 응용력만 발휘한다면, 이 두 가지 데이터 타입을 가지고도 여러 유용한 자료 구조를 직접 구현하고 사용할 수 있는데요. 그럼에도 불구하고 SET과 MAP이라는 2가지의 새로운 데이터 타입을 지원하기 시작한 것은, 프로그램을 통해 생성 또는 수집된 데이터를 좀 더 빠르고 효과적으로 관리하기 위함이 아닐까 추측합니다.
글 중간중간에 계속해서 언급되었듯이, SET과 MAP은 파이썬의 SET과 Dictionary 타입과 완전 동일까지는 모르겠지만, 같다고 치부하더라도 전혀 이상하지 않을 만큼 많이 닮았습니다. 특히 인덱싱을 통해 데이터를 관리하지 않는다는 점이 그러한데요. 이 부분을 바꿔 말하면, 배열로 관리하는 데이터를 정렬하거나 검색할 때 사용하는 선형적인 검색이 SET과 MAP에서는 쓰이지 않는다는 것을 의미합니다. 다시 말해, 해시를 이용해서 데이터를 관리하는 것이 아닐까 추측되구요. 이게 맞다면, 데이터를 검색하거나 삽입, 삭제하는 작업을 배열보다 빠르게 처리할 수 있구요. IIoT 시대에 맞춰서 대량으로 데이터를 처리해야 하는 시대의 추이에 맞춰서 랩뷰에도 변화를 준 것이 아니겠는가 라는 것이 제 생각입니다.
어기까지나 추측이니까, 참고만 하세요. ㅎㅎ
'Programming > LabVIEW' 카테고리의 다른 글
| 랩뷰에서 파이썬 호출하기 (3) | 2024.05.27 |
|---|---|
| 랩뷰에서 파이썬 실행하기 (0) | 2024.05.27 |
| SET 데이터 타입 (0) | 2024.05.26 |
| 배열 인덱스 함수와 배열 부분 대체 함수 (0) | 2024.05.26 |
| 배열 초기화 & 배열 만들기 함수 (0) | 2024.05.25 |
